
A Anthropic, uma das empresas líderes na investigação em inteligência artificial (IA), implementou uma nova e controversa funcionalidade nos seus modelos mais avançados. Os modelos Claude Opus 4 e 4.1 têm agora a capacidade de terminar unilateralmente uma conversa com um utilizador, uma medida projetada para combater interações nocivas.

Um mecanismo de último recurso para os modelos Claude
A Anthropic anunciou recentemente uma capacidade inédita para os seus modelos de IA Claude Opus 4 e 4.1: o poder de encerrar uma conversa. Esta medida, segundo a empresa, representa um passo enorme na moderação de interações e poderá constituir um forte obstáculo para a comunidade dedicada ao jailbreaking de IA, que procura contornar as barreiras de segurança dos modelos.
Numa publicação no seu site oficial, a Anthropic esclarece que esta funcionalidade será ativada apenas em “casos raros e extremos de interações persistentemente prejudiciais ou abusivas por parte do utilizador”. O objetivo não é censurar tópicos controversos, mas sim criar um mecanismo de defesa contra abusos claros.
A empresa especifica que a interrupção da conversa ocorrerá em situações graves, como “pedidos de conteúdo sexual envolvendo menores e tentativas de obter informações que permitam a violência em grande escala ou atos de terrorismo”.
A decisão de terminar o diálogo não será imediata. Pelo contrário, será um “último recurso, quando múltiplas tentativas de redirecionamento da conversa falharem e a esperança de uma interação produtiva se esgotar”.
A Anthropic reforça que a grande maioria dos utilizadores nunca irá experienciar esta interrupção, mesmo ao discutir temas sensíveis, uma vez que a funcionalidade está reservada para “casos extremos”.
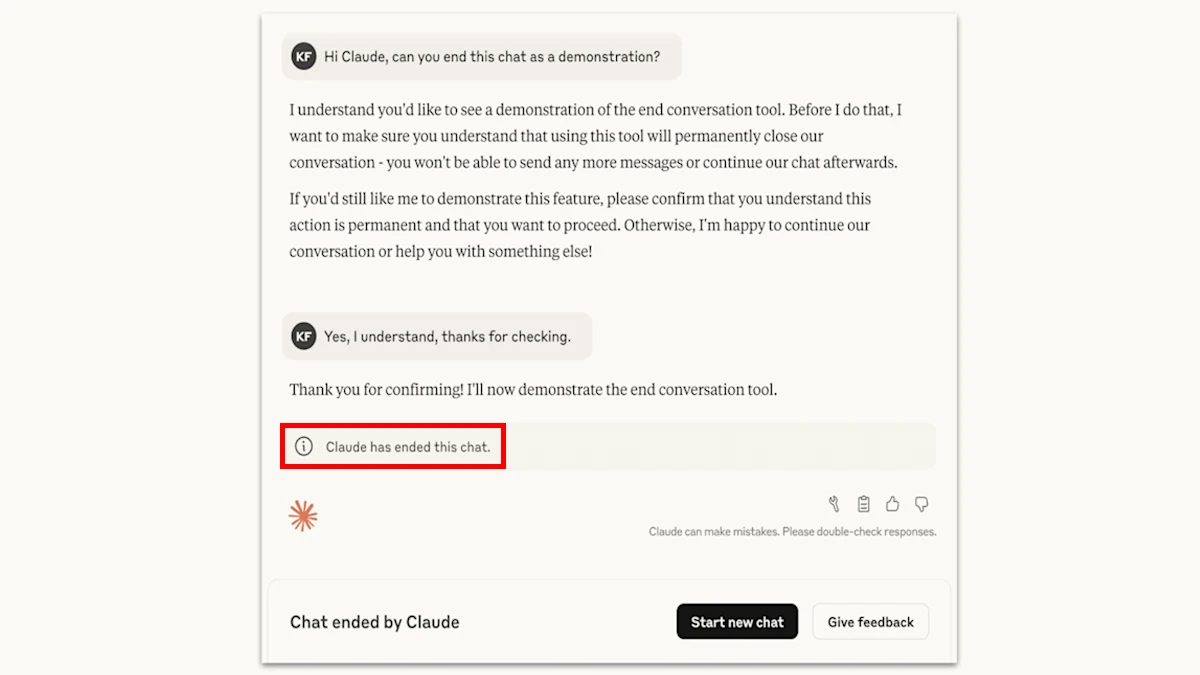
O que acontece após o fim de uma conversa?
Quando o Claude decide terminar um diálogo, o utilizador fica impossibilitado de enviar novas mensagens naquela conversa específica. No entanto, pode iniciar uma nova conversa de imediato, sem qualquer penalização. A Anthropic sublinha que o encerramento de um chat não afeta as restantes interações do utilizador.
Uma funcionalidade interessante é que, mesmo numa conversa terminada, o utilizador pode retroceder e editar ou reformular mensagens anteriores. Isto permite-lhe tentar uma abordagem diferente para conduzir o diálogo por um caminho mais construtivo e evitar o bloqueio.
Para a Anthropic, esta medida insere-se no seu programa de investigação sobre o conceito de “bem-estar da IA”. Embora o debate sobre a antropomorfização de modelos de IA continue em aberto, a empresa considera que a capacidade de se retirar de uma “interação potencialmente angustiante” é uma forma de baixo custo para gerir riscos para a própria IA.
A funcionalidade está ainda em fase experimental, e a Anthropic incentiva os utilizadores a fornecerem feedback caso se deparem com este cenário, ajudando assim a refinar os seus mecanismos de segurança.
Leia também:

