A corrida pela supremacia na inteligência artificial (IA) não se mede apenas pela potência, mas cada vez mais pela eficiência. A Alibaba acaba de demonstrar que é possível treinar modelos de topo com uma fração do custo dos seus concorrentes, como a OpenAI.

A nova era de eficiência da Alibaba
A Alibaba Cloud, o braço de infraestrutura na nuvem da gigante tecnológica chinesa, surpreendeu o mercado ao apresentar a sua nova família de Large Language Models (LLM), a Qwen3-Next. Descritos pela empresa como “o futuro dos LLMs eficientes”, estes modelos representam um salto quântico em termos de otimização de recursos.
Para se ter uma ideia, são 13 vezes mais pequenos que o modelo mais robusto que a própria empresa havia lançado apenas uma semana antes.
Dentro desta nova família, o destaque vai para o Qwen3-Next-80B-A3B. Segundo os seus criadores, este modelo não só é até 10 vezes mais rápido que o seu antecessor, o Qwen3-32B, como também atinge esta performance com uma redução impressionante de 90% nos custos associados ao treino.
Para contextualizar a magnitude desta conquista, basta olhar para os custos da concorrência. De acordo com o AI Index Report da Universidade de Stanford, o treino do GPT-4 custou à OpenAI cerca de 78 milhões de dólares em poder computacional. A Google investiu ainda mais no Gemini Ultra, com um valor estimado de 191 milhões de dólares.
Em contraste, estima-se que o treino do Qwen3-Next terá custado apenas 500.000 dólares. Embora a Alibaba não tenha confirmado valores exatos, o seu artigo oficial revela que o Qwen3-Next-80B-A3B utilizou “apenas 9,3% do custo computacional (horas de GPU)” do modelo anterior, o Qwen3-32B.
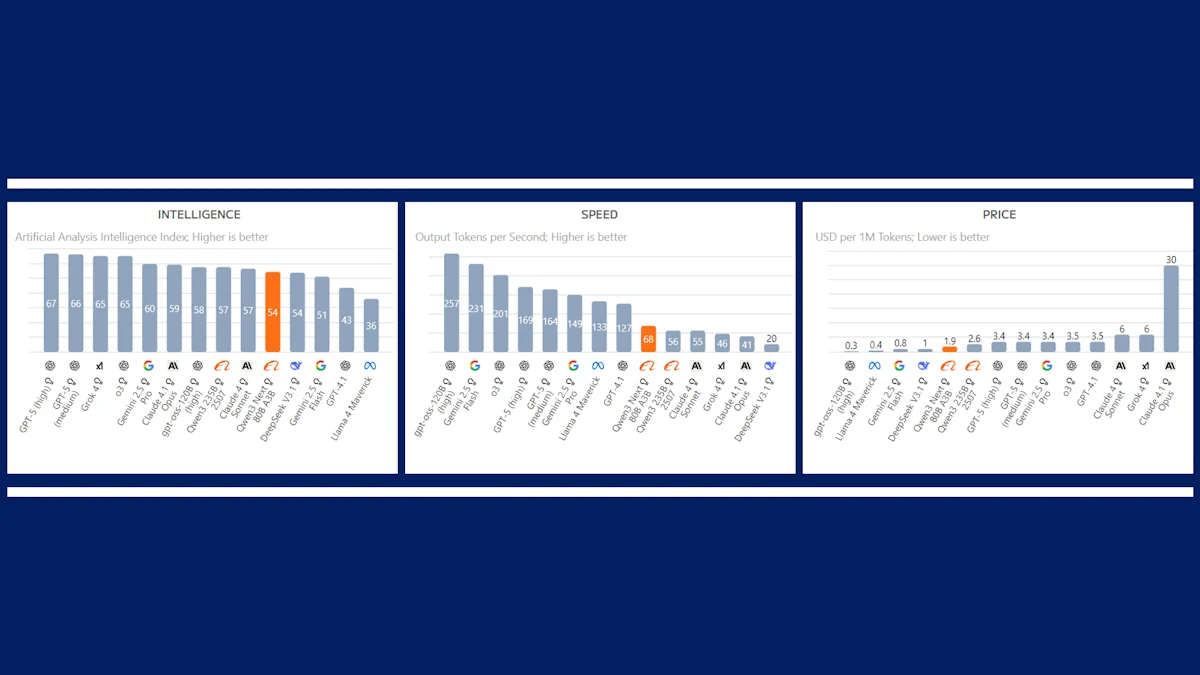
Qual é o segredo para tamanha eficiência?
Os modelos Qwen3-Next utilizam a arquitetura Mixture of Experts (MoE), que divide o modelo em várias sub-redes neuronais especializadas, conhecidas como “especialistas”.
A Alibaba elevou esta abordagem a um novo patamar, utilizando 512 especialistas – um número superior aos 256 do DeepSeek-V3 ou aos 384 do Kimi-K2 – mas mantendo apenas 10 ativos em simultâneo, otimizando drasticamente o processo.
O segundo pilar desta eficiência é uma técnica de “atenção híbrida” chamada Gated DeltaNet, desenvolvida em colaboração pelo MIT e pela NVIDIA. Esta tecnologia refina a forma como o modelo processa a informação de entrada, determinando de forma inteligente que dados são cruciais e quais podem ser descartados.
O resultado é um mecanismo de atenção preciso e extremamente económico em termos de recursos computacionais.
Apesar do seu baixo custo de treino, o desempenho do Qwen3-Next-80B-A3B é notável. Em testes de desempenho realizados pela Artificial Analysis, o modelo da Alibaba superou concorrentes diretos como o DeepSeek R1 e o Kimi-K2. Embora não destrua os gigantes do mercado como o GPT-4, o seu rendimento é excecional quando se considera o investimento necessário.
Este lançamento reflete uma tendência crescente na indústria: a procura por modelos mais pequenos, especializados e eficientes. A Alibaba prova agora que é possível alcançar um desempenho de topo sem necessitar de um orçamento multimilionário.
Leia também:


